
The good news? We are in the very early days of Web3: the experimental period before early adoption when web developers can test tools that will lead to true breakthroughs in computing.
This is how the stage is set by Brooklyn Zelenka: the co-founder and CTO of Fission (opens new window), a company that is building the next generation of web development tools for the future of computing on the edge.
In this Transcription of her insightful talk at the Compute Over Data Summit (opens new window) during LabWeek22 in Lisbon, Portugal, she shares her views on decentralized authentication and the future of Web3.
# Working on Tools and Protocols for the Edge of Computing - 0:07 (opens new window)
I'm going to discuss decentralized authorization: plumbing for permissionless operation. One of my all-time favorite quotes about distributed systems is that the limitation of local knowledge – the fact that data and information in general lives in a particular place and can only move at the speed of light – is the fundamental challenge that we have to contend with, increasingly in the industry and in general.
My name is Brooklyn Zelenka and you can find me anywhere on the Internet. I'm the co-founder and CTO at a company called Fission, where we're working on tools and protocols for Edge and Web3 apps and I work on a whole suite of things. I wish that we had more to say about the interplanetary VM, which is essentially an AWS Lambda competitor that we're starting to work on. Also, private data with a web native file system (WNFS) and Dialog. I'm also the editor of the UCAN Spec that is being used by several companies. Despite not being the only one designing this spec, I might know a thing or two about it.
“In Web3, broadly, we're now talking about doing nothing less than connecting all the world's users and services in an open, inter-operable way, which is something that we haven't seen since HTTP.”
We've waited 30 years to get any more innovation on things that are open, inter-operable and everywhere. For all this to work, it has to be substantially better than Web2. It can't be just decentralized – we have to actually make it work for real workloads, for real people: today, faster and ideally cheaper.
We want to get that whole triangle done right – so how do we power a new Internet?
# The Next Iteration of the Internet - 2:12 (opens new window)
The Internet is about 30 years old and really comes from an era where your cell phone had a telescoping antenna that you had to pull out. Where all of your compute happened on a beige box under your desk that didn't have the power to run anything. You always had to talk to, essentially, a mainframe to get results back. That's no longer the case, but we still have to now contend with the fact that there's locality and, especially, data locality.
So, as we might know from physics, you're stuck in a light cone and if we send messages or data between things, they can only move so fast and only over a certain size of pipe.
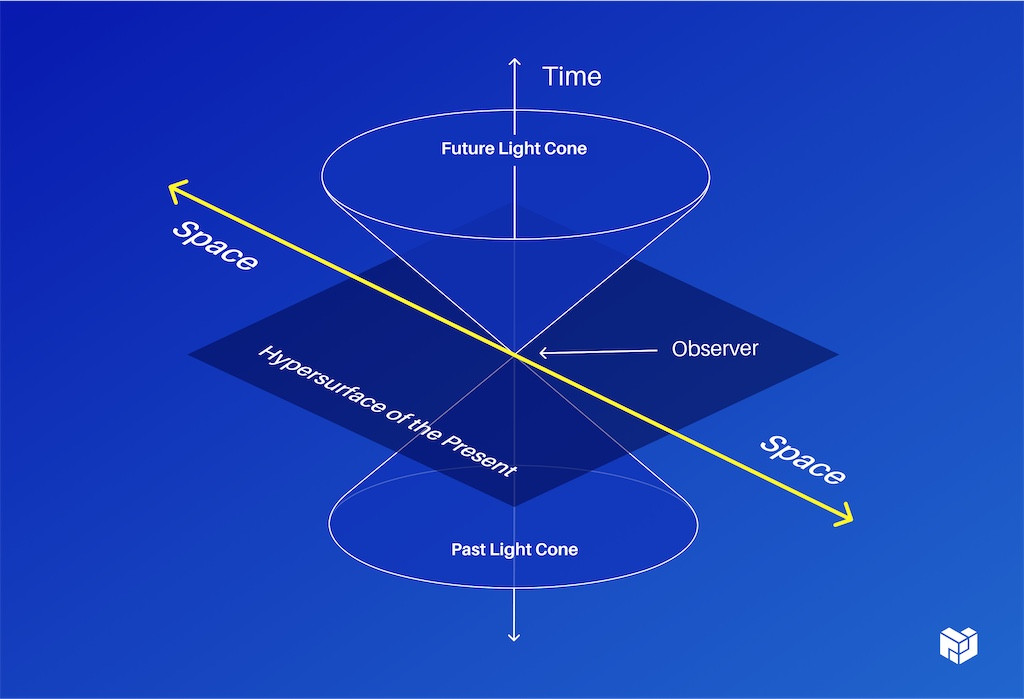
Even if I send messages in multiple places at the same time, they still may arrive in a different order and can only move so fast. Once you have enough gravity of data, they literally can't move it fast enough around because of physics. This isn't something that we can solve with fancier computer science, so we're here because we want to do compute over data. In order to do any kind of compute, you obviously need data and to do data in production, you have to have some kind of auth.

It's a little strange in some ways to talk about auth in a compute setting, but in order to do any of this, you have to have auth. A typical picture today looks something like this: you have developers who want to interact with some services. Maybe some of these have access to data and the others don't. And they'll connect to one of these and then, maybe, these are all networks together so that they can get access to that data.
So each of the services have to have individual agreements with each other and the developer has to pre-negotiate some tokens with all of these, but this isn't what we want. This is just how it happens to work. With things like content addressing, we can liberate this picture from needing access in a particular place. We've made it possible to have a universal location. With capability models (like what we're going to talk about today with UCAN), we don't need pre-negotiation either, so we can just move freely around both the compute and the data around a network.
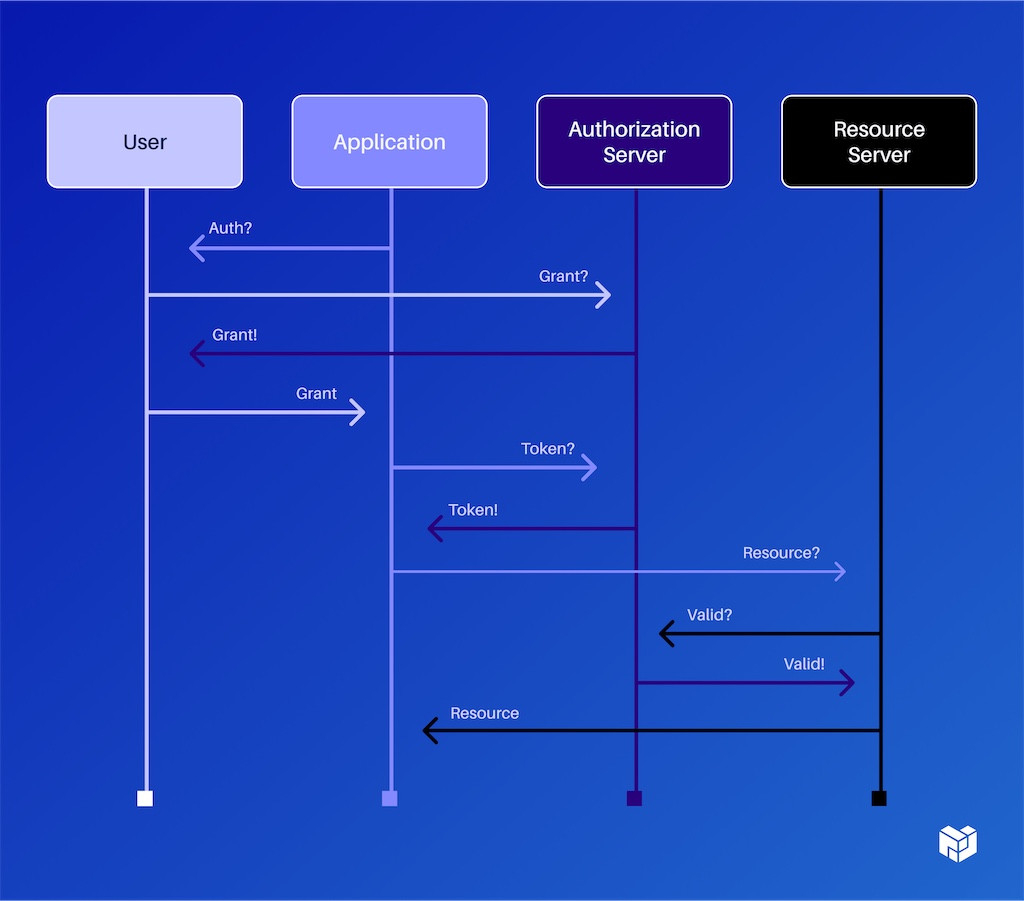
Historically, people have used things like OAuth to solve this problem. A typical OAuth flow has four agents from the user and the authorization server. There are 10 or 12 steps just to get through and this fundamentally places things in a certain location. You have to have an authorization server that says: “Here's the list of who's allowed to do what.”
By comparison, if we use capabilities, we can make this picture much, much smaller and this is actually being generous to OAuth. It could actually be just two of these arrows and nothing else. This is using capabilities, but it looks like a regular Google login-style step:
- I want to give access to these bits of data or this compute resource.
- ‘Are you sure you want to do that?’
- Yep.
- Then, you can jump right into the application.
# A Closer Look at Authorization Networks - 6:12 (opens new window)
I said this word, ‘UCAN,’ a few times now. What exactly is UCAN? It is a user-controlled authorization network. If you're familiar with DIDs and public keys: DIDs say who you are and UCANs say what you can do. This is the distinction between authorization and authentication.

They look like this:

The default encoding is just a JWT, so it moves around as a you know base64 string that decodes to custom JSON. It is a different auth model than what most people are familiar with. ACLs hav been around since at least the 70s and it's just a list that says who's allowed to do what, as opposed to capabilities, which act a little bit more like a ticket.
# A Metaphor to Explain ACLs and Capabilities - 7:06 (opens new window)
So, we'll look at that in a little bit more detail. For example, say some user wants to access some service and they send a request that gets stopped by another process. That's essentially the bouncer or some guard who checks their list and then, maybe if that user is on the list, they will be allowed in.
On one hand, this is nice because it's broken up into these separate segments, but it puts the ones that are actually interacting not in control. It puts this process in control, which means that you need to have this list in one place and so you're stuck now with auth locality.
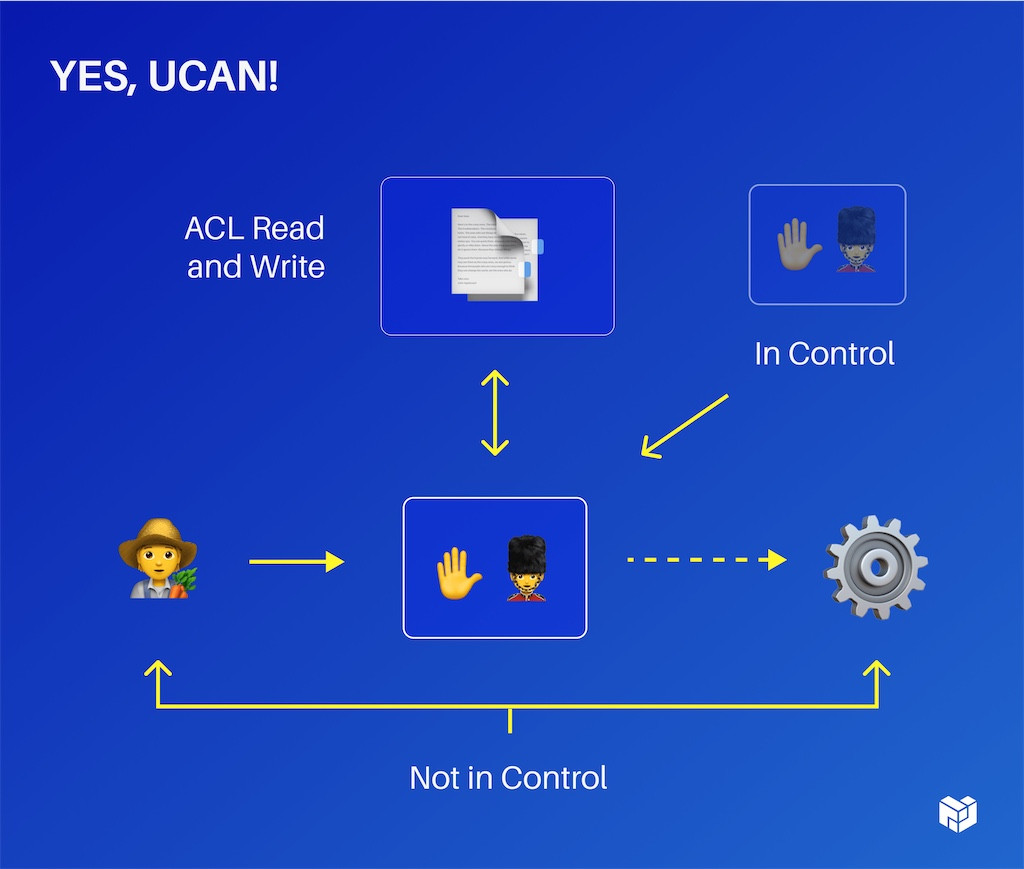
You always have to go and you're always contending with the speed of light to get this to move around.
Further, if you can gain control of this Deputy, (as it's sometimes called) you can do whatever you want. You have a system admin go bad and do whatever they like and that's because they're the fundamental ones that are essentially the super admin for the system – not the service, not the user.
Sometimes, capabilities, by contrast, are kind of like tickets to go see a movie. When you go to see a show, you just know where it is. You're given a ticket and they don't know who you are, you just hand it to them on your way in. So it's just this ‘Admit One.’ These are in control. You can carry the ticket with you as you're walking around to do your various things. If you can't make the show tonight, that's fine. You can hand it off to somebody else and say: ‘You know what, go see the movie instead.’
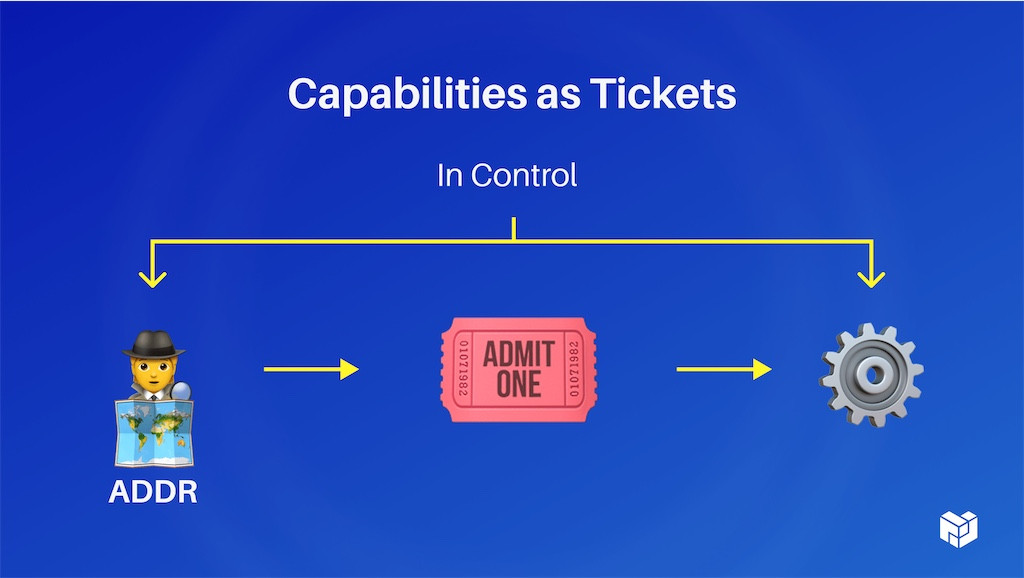
Where the metaphor breaks down a little bit is as follows: You can make copies of these if you need to and you can delegate sub-rights inside of it to someone else, which would, in the movie scenario, be if you had a movie festival pass you could delegate. You can go on Tuesday, but not the whole thing. If you come from a blockchain background, these are a little bit like state channels, but for auth and they can do some things for composition that ACLs don't.
Rights amplification is the composition of your authority across multiple systems. The metaphor that's always used for this is: if you have a can of soup, you can't do much with it and if you have a can opener you can't do much with it. But if you bring them together, you can have a delicious soup.
So if you have Auth to read some private data and to do a computation on completely different systems, you can compose those now without having to pre-negotiate both systems. You can just say: ‘Hey, here's a certificate that says go read from over there, take this thing and run it.’ That's it.
To get right down to brass tacks, this is how an actual certificate looks: it has a header, just like a regular JWT. It has this payload and then a signature.

The signature has to match the issuer, which is contained to the payload so you can prove that this is who it came from. It has a description of what you're interacting with or what you're granting permission over and what you can do with it. That's openly extensible. There's nothing in the system that says: these are the things you can do. You can define completely your own as long as the other service understands what that means and this is just a noun and a verb, that's all. They're fully extensible. You can add whatever other data you need as well.
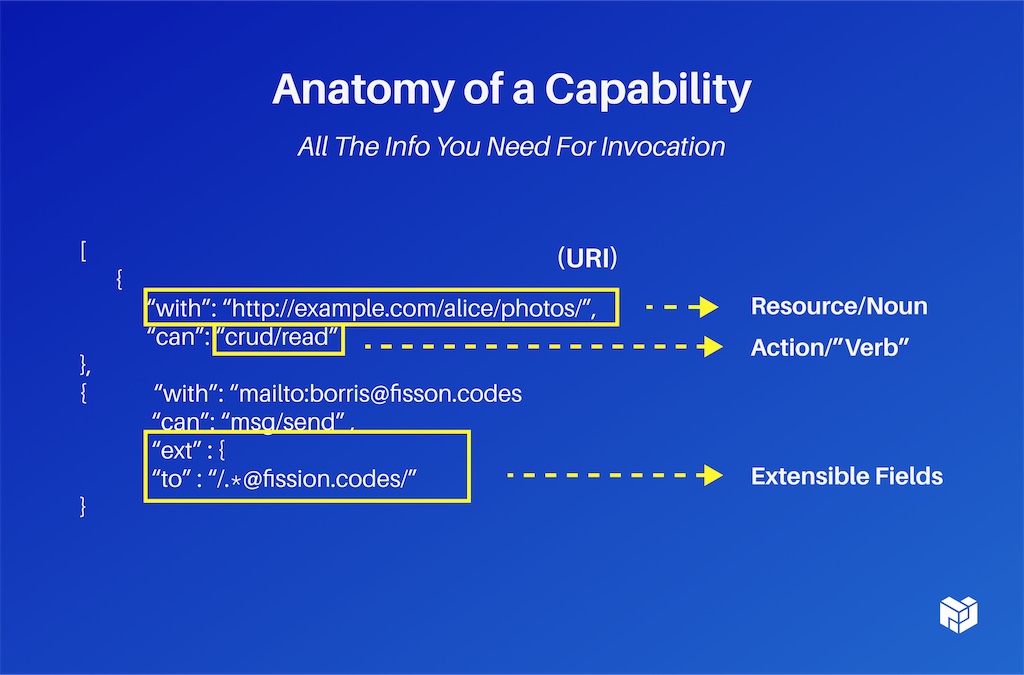
In this case, we're saying you can only send emails to people at a Fission codes email address. This is also all the information you need for invocation, so you don't actually need a separate system now to say: ‘And please run this.’ It's: ‘Hey, do this thing, please.’ Run this ‘wasm’ over this data and it can be both the auth and the invocation call. So you can do distributed RPC as well in the same model. You probably don't want to invent your own whole set of resources and abilities, so there's a standard library for many of the really common ones, like mail servers, file systems, and credit actions.
You can take those and make them even more powerful by saying: ‘Okay, I have a read capability out of the standard library, but I'm a photo application and I want to narrow that down further to publishing into an album. You can just define that and anybody else that you're collaborating with just needs to understand what album ‘publish’ means and that it is backed by this read action and everything works. The way delegation works in the system is you have a chain of who originated the resource all the way down to who's consuming it – as long as the resources and actions get narrower as you go down.
If I have the ability to write into an entire file system, maybe I can give somebody else access to write just into the documents folder. By creating a resource, I have full access over it. I'm the admin. I can then point to: ‘Hey, this is from me to somebody else with some subset of my rights’ and then they can do the same thing. ‘Okay, here's to somebody else’ and a subset of those rights and so on. And because we can follow this chain backwards from this last invoked one, they contain all their parents or at least references to all of their parents or contents are dressed. We can verify this anywhere – it doesn't have to be at a particular place. I can just walk around with it. This works offline.
This even works in the browser – so with things like WebAssembly and Offline Compute, you don't necessarily need to go to an external system. We can keep stuff completely off the network in a lot of cases and not have to deal with that 200 millisecond round trip time.
All of the browsers now have WebCrypto API, which means you can have non-extractable keys: a public-private key pair, where the private key isn't viewable to anyone and it's completely managed by the system. It never leaves the system, doesn't move around. And we can link between them now in a perfectly secure cryptographic way that still preserves user agency, data locality, and reduces the amount of stuff that we have to have to put on the network.
If I'm going to run a query over a database, we have content addressing. I can pulldown the subset of the database I care about, run queries over it, make some updates and then atomically push the diff, for example.
# Plugging together applications - 14:20 (opens new window)
Alan Perlis said: ‘Every program has at least two purposes: The one that was designed for and the one that it wasn't.’
“We want to enable all the things where people didn't expect to plug things together.” - Brooklyn Zelenka
Imagine a user who's signing in with MetaMask and an Ethereum account and they have several of these Emojis representing different resources and actions that they can do. She wants to collaborate with this other person and says: ‘You know what, you can manage everything for me directly in Chrome.’ And he says: ‘Ah, you know, I actually also need to use this on my iPhone, but sometimes I leave it out, so I'm only going to do some subset of things on that.’
As a result, he delegates between devices. This isn't per person now, this is per software agent and can delegate that on further to somebody else working in Brave. But it doesn't have to go in this direct chain. You can delegate as many times as you like. Polygon has a completely different set of capabilities as is across the top and a WebAssembly function in the cloud. And, finally, somebody working in Firefox can take these two farther down the chain and bring them together.

Now, they have access to both these and aren't limited to a single application. Maybe there's Twitter at the top and a spreadsheet application on the bottom left and some science app on the bottom right, so the certificate doesn't care. We can plug these systems together now without having to worry about Twitter's token format. Twitter hasn't adopted UCAN yet, but in this glorious future, we don't have to worry about what their specific API looks like. Regardless of their specific token format, we can just attach all these things together like Lego with zero coordination ahead of time.
At this stage, people usually ask: ‘Okay, that's great, you have all this stuff moving around the system. How do I revoke things?’ And the good news is: we have content addressing. As long as you're earlier in the chain, you can sign a revocation and gossip through the network to say: ‘Hey, you shouldn't trust this specific one and anything downstream from there.’ So if someone on the Chrome browser revokes this Brave browser user, but not the one in the middle, the downstream consumer of that also can't use it.
Let's look at a nontrivial example. This is a relatively complex UCAN.

This looks like lots of random letters and numbers. We won't go through every layer of it, but just to give you a flavor, here is that same token format that we looked at earlier. It has two proofs in it (highlighted in purple and green below). These are just other base64 encoded UCANs. Here is what's happening under the hood.

Then we can take one of those, for example, the purple section, and unwrap it and look inside. We can say: ‘Ah, okay great, on this previous one I have the ability to append into a photo directory and into a notes directory.’ One of my proofs gave me the ability to append into photos, so I'm always narrowing down – or at the same level as –
my proofs.
People started building tooling around these concepts, as well, to help explore all of these proofs, the proof chain, and whether the signature is valid. It's a little application at UCAN.xyz. Basically, you can just paste one in and it'll decompose it for you and say: ‘Here are all the moving parts.’ Then, to explore all of the proofs in the delegation chain, you can click through along the bottom.
You can see that, for example, one has three proofs and you can choose to see proof one or proof three, then drill down into the chain.
# Early Days for Web3 – And What’s Next - 19:38 (opens new window)
It's still extremely, extremely early days for Web3. We're just figuring this stuff out right now. I would say that we're not even at the classic chasm yet, we're at the smaller chasm, but it's growing fast.
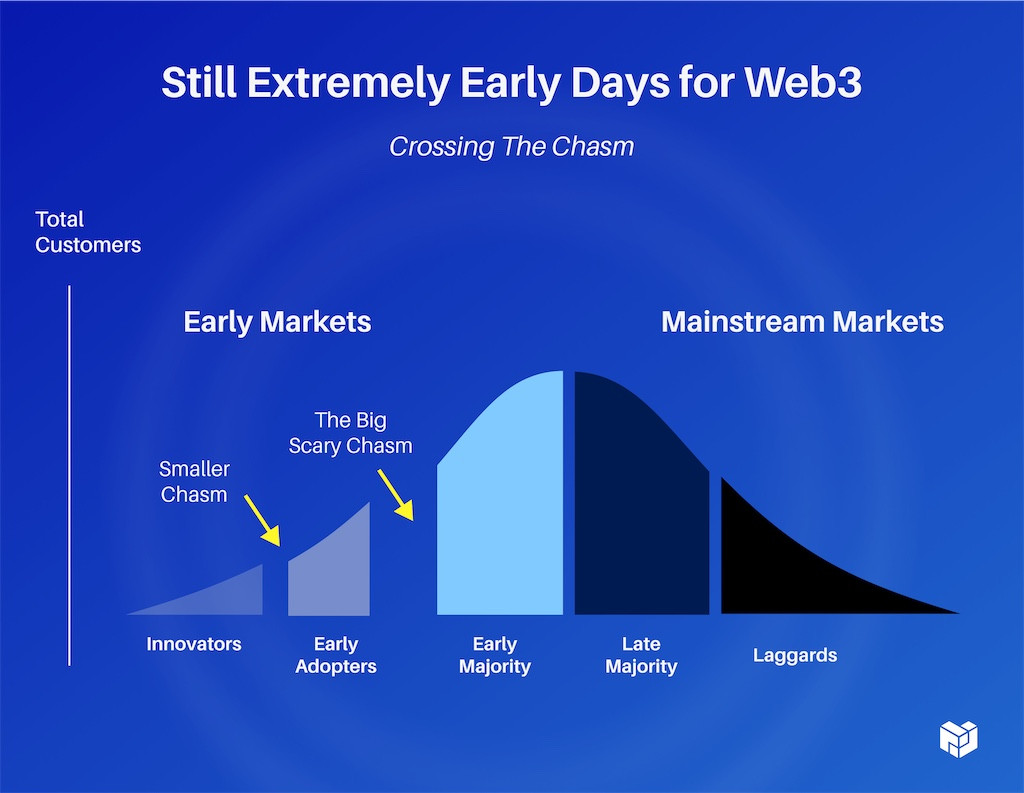
If we're going to compete with Amazon, Google and Azure, we need to find ways of plugging our stuff together. We don't even register in scale against them yet. We want to find ways to leverage everybody in the community, all those smart brains, projects and efforts, to not need to reinvent the wheel every time and have a winner takes all mentality.
We have content addressing. We can move things around and we can push compute to particular places. At the end of the day in Web2, service composition is too hard for devs. (D)app UX is too hard for many users. I would argue that a concept of (D)app doesn't even exist. You have applications that users use and (D)app UX is too hard for most. No one today is in control of either their data or their compute and we want to put that directly in users hands or in the service provider's hands without having to always go through one of these giant systems.
We're building on top of standard, well-understood technologies, aiming to be a Trojan Horse and get it in basically everywhere.

One of the teams building a tool on top of UCAN really loves the ability to encode as a JWT, because it works with all of their existing tools. It plugs right into their Rust server as a bearer token in the header and it decodes it for them. They then have to plug it into a UCAN library to actually understand what's happening inside of it, but the actual ingestion pipeline just works straight out of the box.
They're in a sort of Web2.5, but there's nothing saying that you couldn't do this in a pure Web2 space. We want to connect Web2 and Web3. We need to play nice with others, plug into existing systems, bridge into existing standards and make it easier, more secure and more open than existing systems like OAuth, X.509, SAML, Metamask etc.
Thank you.