
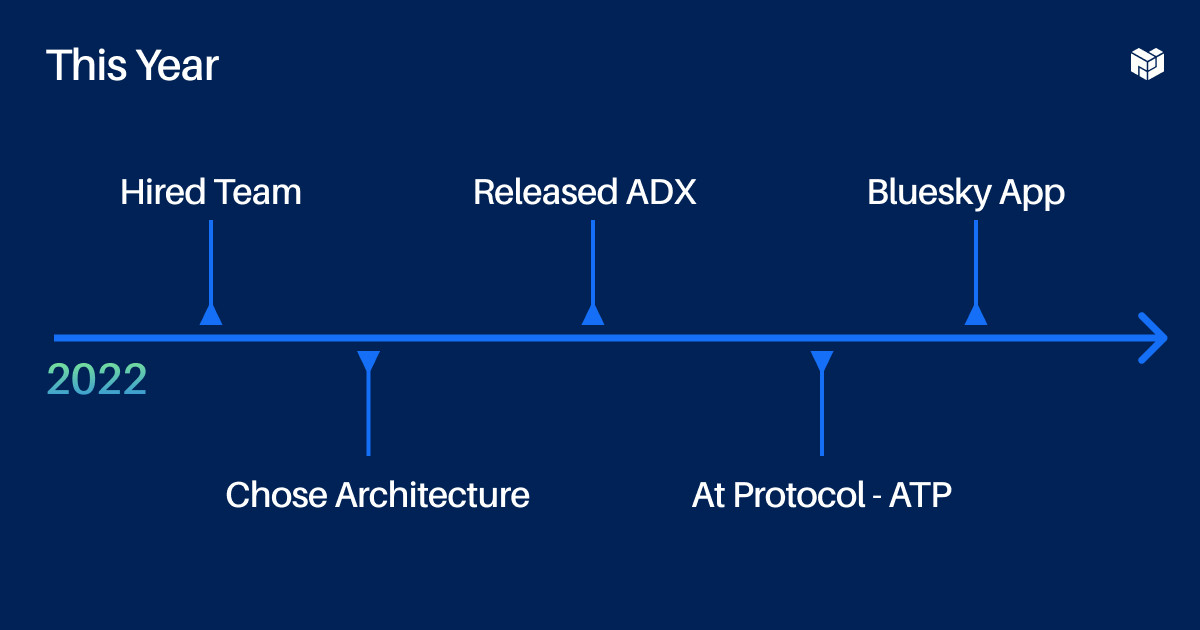
In 2023, Bluesky (opens new window), a decentralized social network using IPLD, launched an invite-only beta and gained mainstream traction almost immediately.
The promise? Social networking that offers creators independence from platforms, developers the freedom to build, and users a choice in their experience.
The Bluesky story goes back to 2019, when then-Twitter CEO Jack Dorsey suggested the concept of a decentralized social network amid challenges in the sphere of public influence and democracy. A team of experts was formed to craft the solution. Shortly after, Twitter chose Jay Graber, former founder of Happening, Inc., and an early engineer at Zcash, as the project lead. Bluesky was born.
Today, the client app Bluesky is built on top of the AT Protocol, or authenticated transfer protocol. AT Protocol has three main components: a federated network, a DID base identifier, and user data stored in repos. All these components were selected to ensure length infrastructure and a strong base layer of portability.
In this Transcription of her insightful talk at IPFS Camp (opens new window) during LabWeek22 (opens new window) in Lisbon, Portugal, Graber shared the build of Bluesky, the logic behind the concept, and insight into future plans.
Hi, I'm Jay. I run Bluesky and we are a company building a decentralized social protocol that uses IPLD. You've probably heard of us in association with Twitter since we started out as a project there, but let me give you some brief background to catch you up on who we are and how we started.
# Why We Need Decentralized Social Media - 0:18 (opens new window)
In 2019 Jack Dorsey, who was Twitter's CEO at the time, announced that they'd be funding a decentralized social protocol. In his initial tweet, he listed four reasons why Twitter would be funding this project:
- Centralized moderation isn't going to scale over the long run.
- Social media is increasingly about curation. Users and developers don't get enough freedom in the current environment where algorithms are proprietary.
- The incentives of social platforms push towards promoting content that generates outrage and this doesn't seem very healthy for society.
- New decentralized technologies make it seem possible to rebuild Twitter as a protocol in a way that didn't seem possible 10 years ago.
I agree with most of these reasons and I also think that decentralizing social media at a technical level doesn't, by itself, necessarily solve all these problems, but it distributes power over the network and allows many more entities beyond one company to build solutions, and many more communities beyond the community of one company to self-govern their part of the network. That this is really the right approach to start solving these problems at the higher levels.
# Origin of Bluesky - 1:32 (opens new window)
In 2020, Twitter brought together some outside collaborators in a Matrix chat room, including myself, to discuss the problem space. I wrote up an ecosystem review that compared existing decentralized social networks. In 2021, Twitter chose me as
the project lead.
So, I set up an independent company to build out the vision for Bluesky. I proposed: I did not want to be a part of Twitter at the time because I figured a lot of things could change, and even though Twitter wanted to really work closely with Bluesky at the time, who knows what could happen in the future.
I'm really glad I did that, because it's a pretty vulnerable position when democracy depends on discourse happening on social platforms that can be so quickly changed.
Centralization is a structure that lends itself to rapid change and that change can be for good or bad. Now that we know the basics of how social media works, it might be healthier to turn it into a more stable, neutral infrastructure layer for public conversations.
# Core Design Considerations - 2:29 (opens new window)
In 2022, I received some funding and then I hired a team. We have three developers on the team. We have a range of experience across centralized social protocols and traditional web services and could use a few more developers — like a mobile dev, front-end UX engineer, and a good protocol engineer. Get in touch if you want to join.
We also have some great technical advisors, like Jeremy Johnson, the first engineer at Protocol Labs, who helped build IPFS, and Martin Kleppmann the author of “Designing Data Intensive Applications (opens new window),” who's done a lot of research on distributed data structures. With this team on board, we did some more research and settled on a technical architecture this year. We had four major design questions: how do we make the system (1) usable, (2) scalable, (3) portable, and (4) accountable to its users?

We want it to be as usable as mainstream social applications so users don't have to learn too many new things. I just don't expect most users to want to figure a new system out. We also want it to be as scalable as mainstream social applications. That way you can have billions of users without running into performance limitations that require you to be doing novel R&D on the fly.
These considerations suggested that we'll need some traditional service providers, like hosting services, but if there are entities in the network like this we want user data to be easily portable between them so users don't get locked in. For any entity that ends up with power in the network, we want mechanisms that help keep them accountable to the users. This can include tools for transparency into their actions or just the right tools for users to exit.
# Choosing the Right Architecture - 4:01 (opens new window)
The three main architectures for decentralized social networks that we looked at are:
1. Federated
2. Peer-to-peer
3. Blockchains
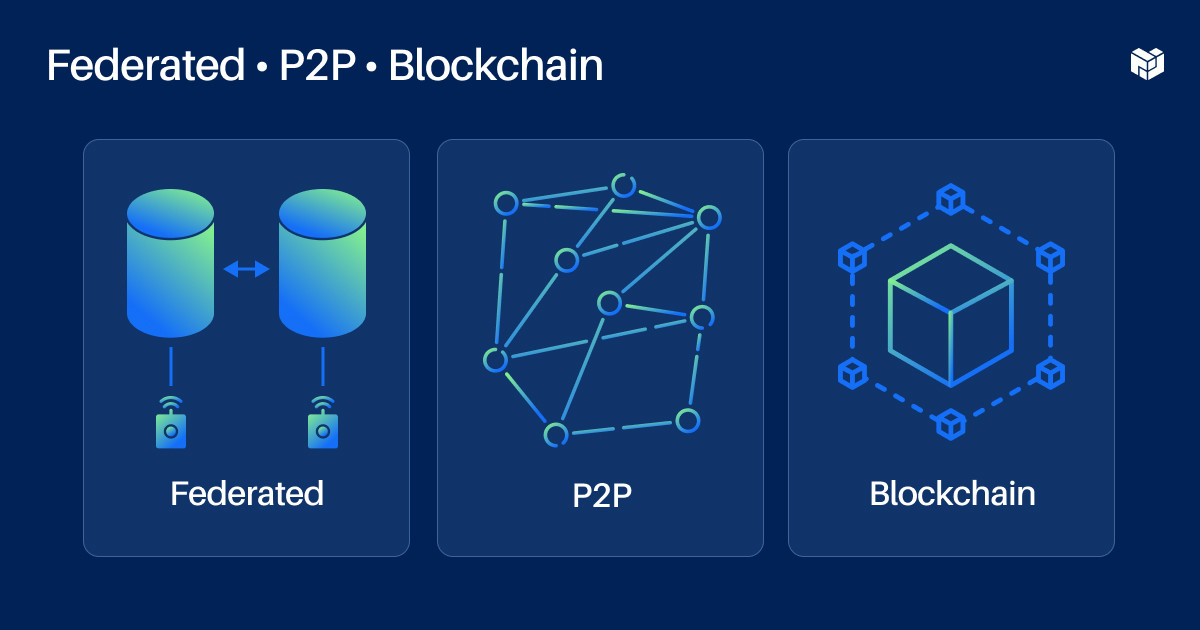
Federated networks have a familiar client-to-server architecture. The servers just talk to each other. Peer-to-peer applications distribute network functionality across many peers. Blockchains are global data structures that are logically centralized but politically decentralized, and so this makes them useful in cases where you need global consensus, but your system is decentralized. It's still an expensive way to get consensus and if you're not trying to put all the data in your network on a blockchain — which I don't think you need to — you still need to choose architecture for the rest of your network. You can put data from a federated network on a blockchain, or you can use blockchains as a global database for some use cases in a peer-to-peer network.
We decided to make our design blockchain agnostic. The protocol doesn't need a blockchain, but if you wanted to register a user ID on a blockchain, we accept decentralized identifiers so the system could become compatible with doing that.
<!--
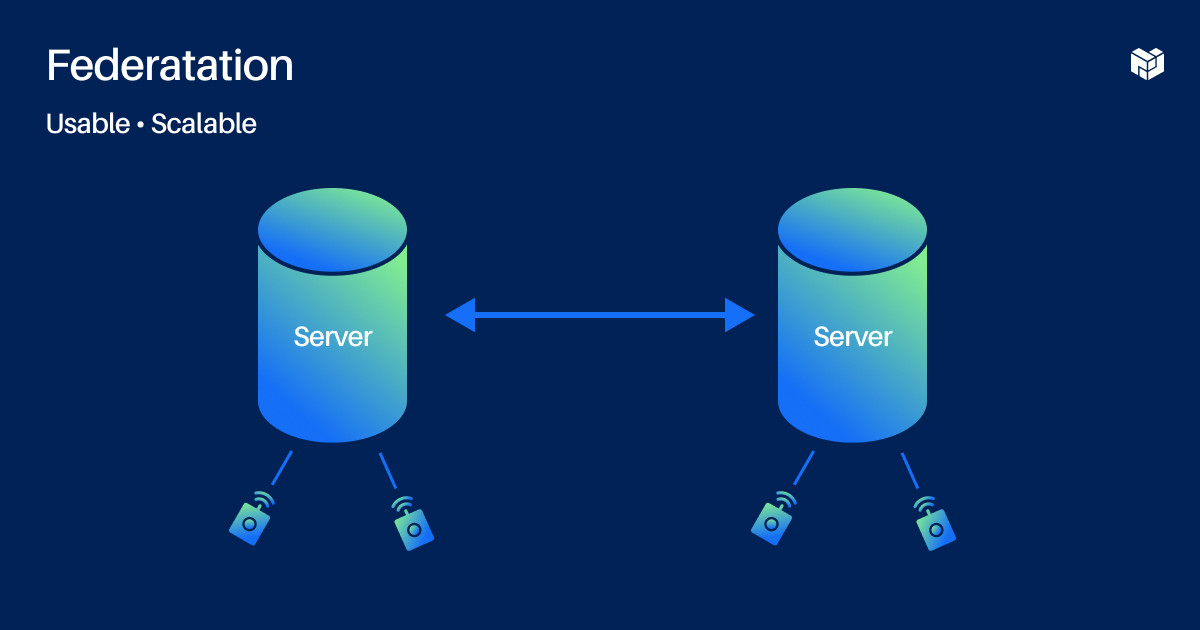
When comparing federation and peer-to-peer, federated networks are very usable and scalable in familiar ways for users and developers. You have a username and a domain like “Alice@bsky.app.” The problem is you can get locked into the site you sign up at. If you sign up at bsky.app it's hard to move—even if the network tries to help you move, like by doing a redirect user server. If someone looks up “Alice@bsky.app,” bsky.app has to say “Alice, move to food.com — go over there.”
But what if bsky.app unexpectedly disappears? Alice is out of luck. The users lose their identity and their data and they have to start over from scratch or somewhere else.
Because it's hard to leave and because there's very little transparency into what a server is doing with your data, there's not much accountability for servers in a federated network. If centralized platforms are governed like monarchies, federated networks are governed like little feudal societies. There isn't just one king ruling over the whole network but there are smaller lords who still have absolute power over their domain.
To mitigate these downsides of federated networks, we borrowed some properties from peer-to-peer networks, mainly cryptographic IDs keys and content-addressing hashes. We call these properties self-authenticating, meaning the identity or data can be independently verified without a server, although you can have one for convenience.
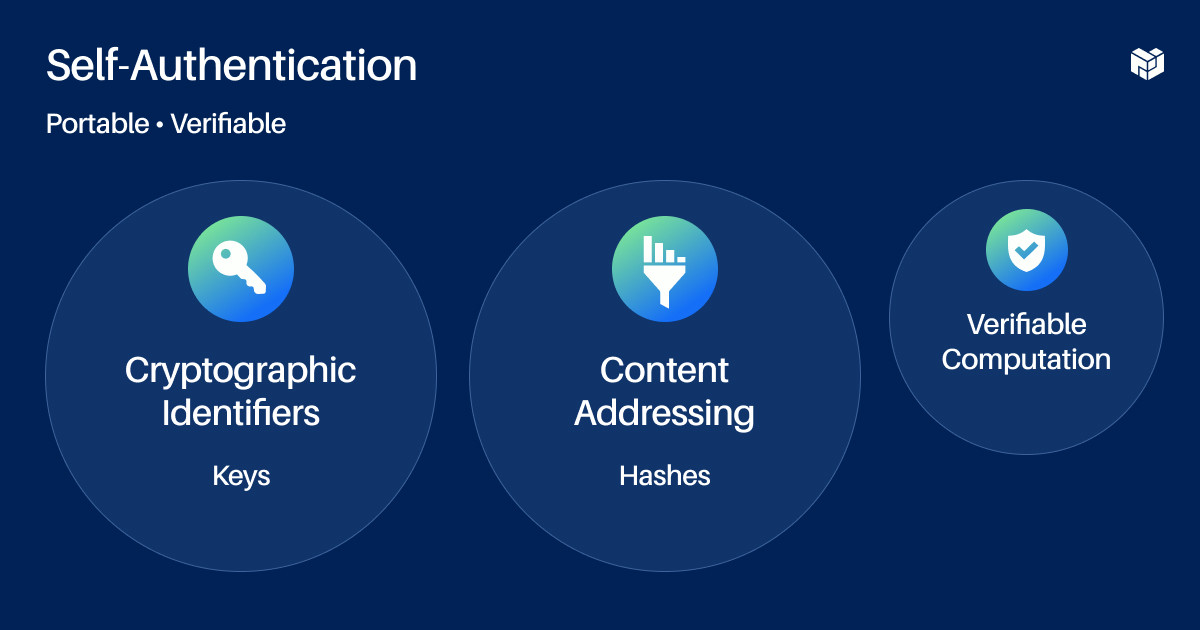
Self-authenticating components don't need to be exclusive to peer-to-peer networks, but peer-to-peer networks use them because they don't have servers to act as authenticating authorities.
Another possible component of self-authenticated protocols is verifiable computation, like zero-knowledge proofs. These groups can add transparency and verifiability to computation that's been performed, and there are a lot of new use cases this could unlock. This is outside the scope of our current design because it's new and complex.
Peer-to-peer social networks use cryptographic IDs for user identities. This means that instead of your base ID being like “Alice@bsky.app,” it would be this long string of characters representing your public key. You can give this key a nickname, like “Alice” but there's nothing unique about that nickname, and you can't find the user by it.
To find people in the network at all, you usually have to introduce some kind of super node that has more visibility and connections. SSP calls these nodes “pubs.” I don't think it's a bad thing, but it's just something we've observed, which is that even if you try to keep your peer-to-peer network really flat, centralization tends to emerge when you start optimizing for convenience and usability.
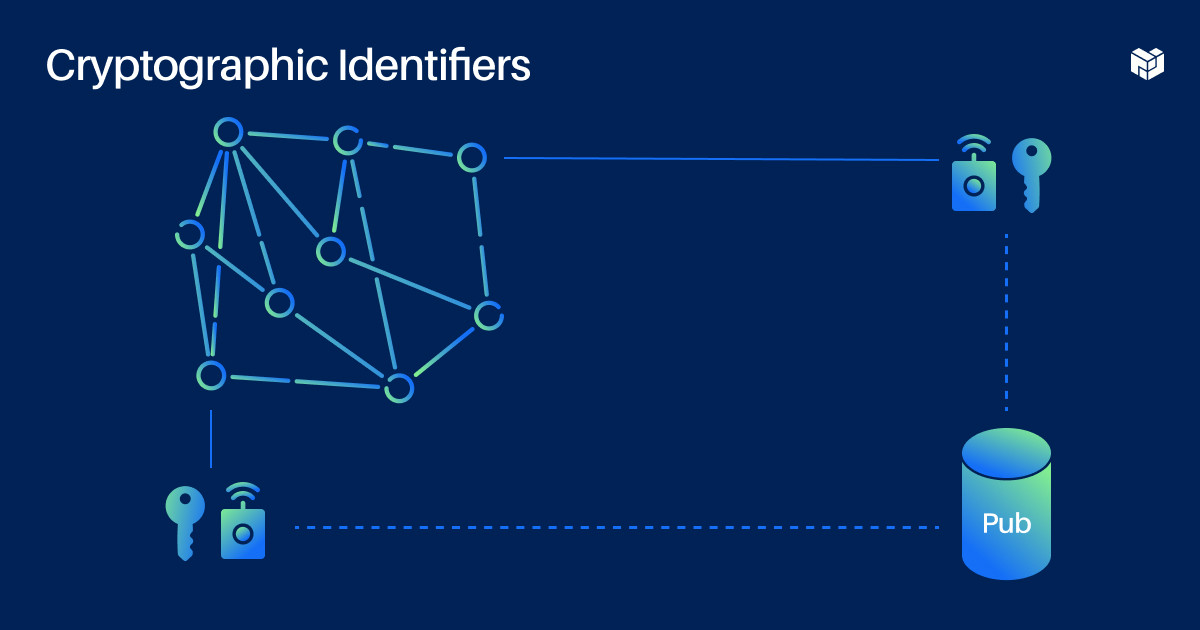
IPFS uses content addressing to find data by hash rather than by location in the network. Instead of needing to know where something or someone is located, you can just look them up in this distributed hash table. To use this in a web app, you usually need a gateway, which is another example of reintroducing this element of centralization when you try to make things really usable and convenient.
Given that peer-to-peer networks have these really cool self-authenticating properties but tend to end up reintroducing centralization for convenience, we decided, “Why not just start off by assuming servers are going to do the heavy lifting to create a good user experience?”
# Bluesky’s Architecture - 7:53 (opens new window)
Our architecture combines servers, cryptographic keys, and content addressing.
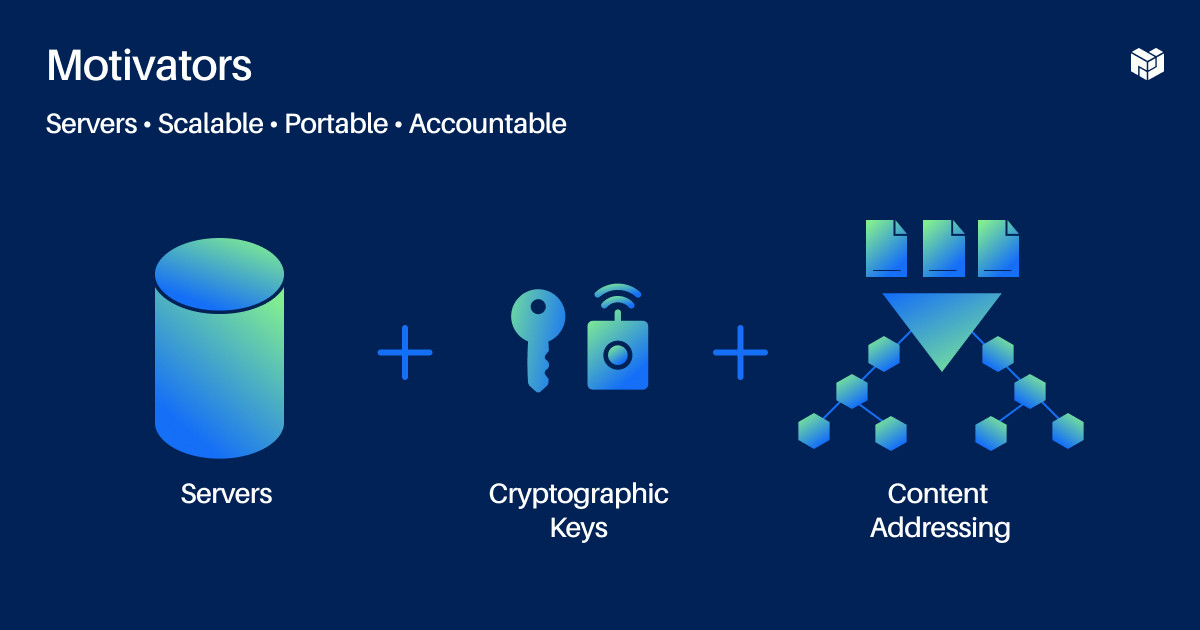
The first draft of the protocol we put out was called ADX, or the authenticated data experiment, which we released on GitHub earlier this year. Now it's called the AT Protocol, or authenticated transfer protocol. It's maturing but it's still not done, so if you go look at the specs you're going to find some to-do's. But I can talk about the overall structure here.
# The 3 Components of the AT Protocol - 8:17 (opens new window)
The AT Protocol has three main components as well as a schema system, which I won't get into, but it is an approach that optimizes for compatibility between different implementations.
- Network: Federated - The network architecture is federated, so there are clients and servers.
- Identity: DIDs - The base identifier is a DID or “decentralized identifier.” This DID connects a human-readable name, like Alice.com, with a public key. The DID method we're currently using, “DID PLC,” is really just a placeholder until something better comes along, but structurally we think this is probably the right approach.
- Data: Repos - User data is stored in repos, which are analogous to Git repositories. It's these repos that use IPLD to content address every record, so Git and GitHub are good analogies for how this is going to work.
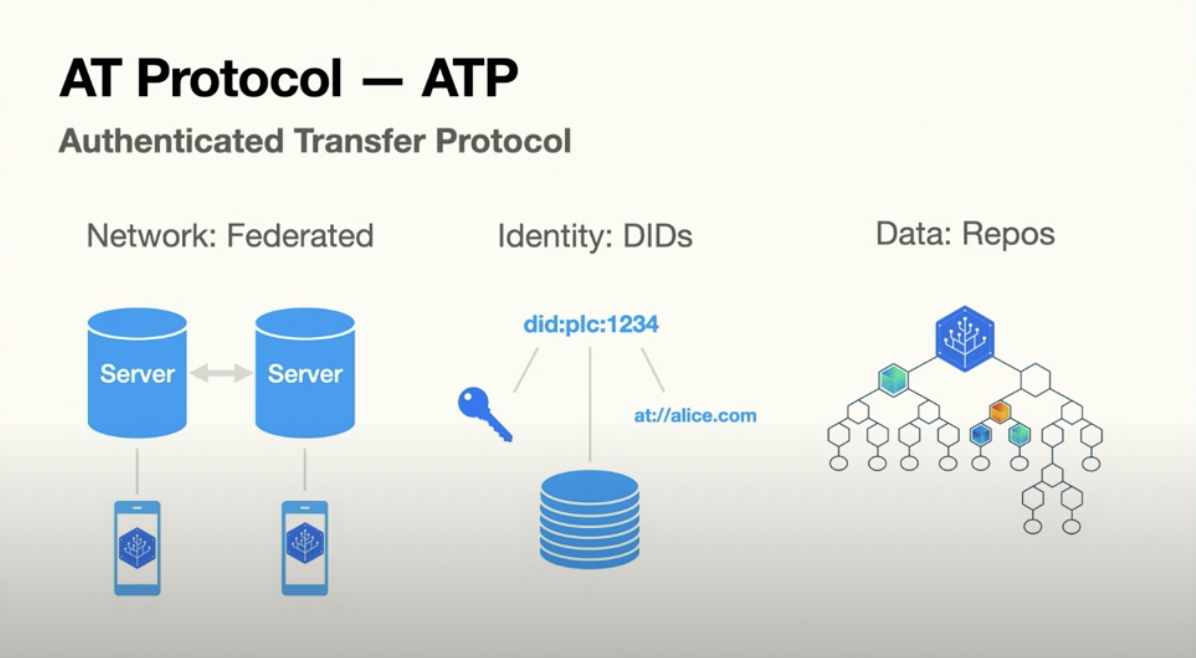
Imagine if your social account was hosted in Git repository and you could use a site like GitHub. We could also easily move to an alternative, like GitLab or Bitbucket, this is the relationship between the user repos and the servers that we call pds's or “personal data servers.”
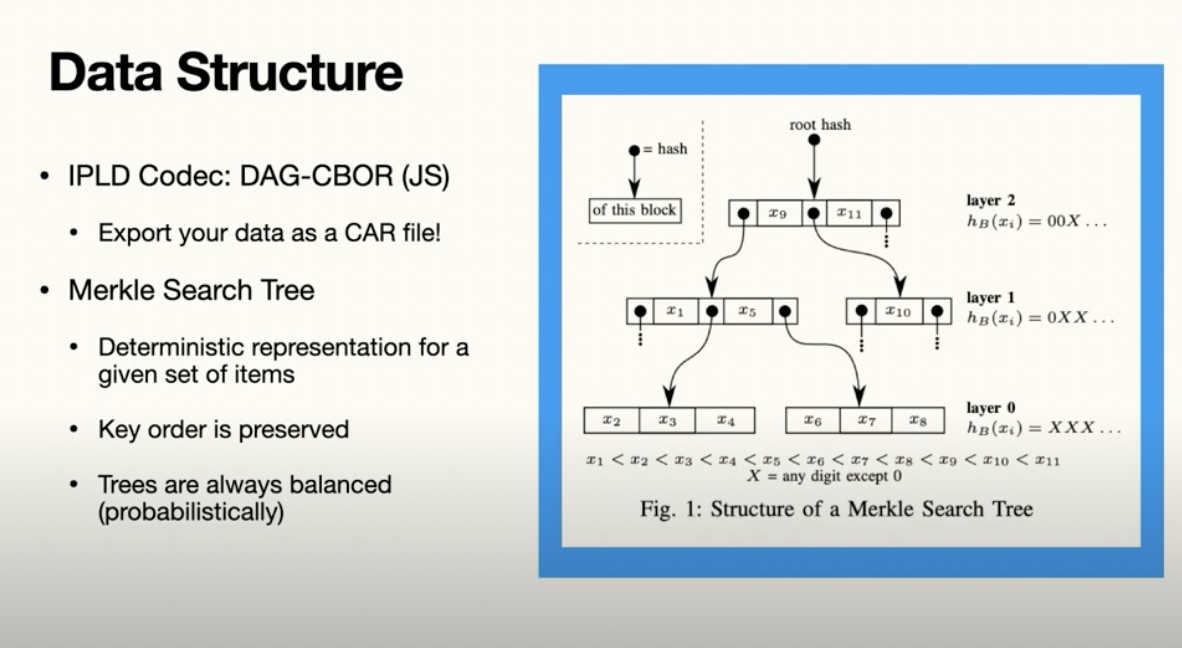
The IPL decodec we're using is JS DSG-CBOR. It's working pretty well for us. The cool thing about the IPFS ecosystem is it already has tooling for working with Oracle DAGs, so you'll be able to export your social data as a CAR file right from the start and play around with it. The specific kind of Merkle Tree we're using is the Merkel Search Tree, and a nice property is that trees are always probabilistically balanced.
# Overview of the AT Protocol Network - 9:32 (opens new window)
To wrap it up, here's a high-level overview of the AT Protocol Network.
- Users have a human-readable username and a key, both linked through a DID. The user keys are currently on the server because we didn't want to get into client-side key management right now as we weren't super confident we could create a smooth user experience for that. It's possible to do though, and that's something that we'll definitely pursue in the future.
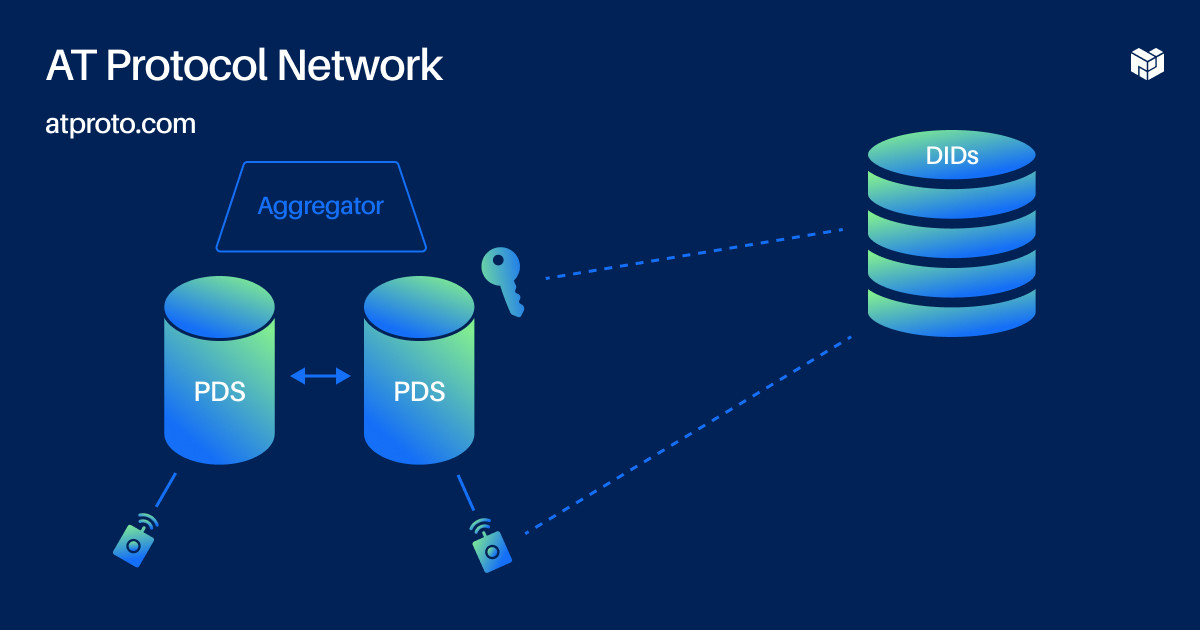
The servers federate with each other. They do this to get a global view of the network and do things like search for a trending hashtag or receive curated feeds. There are aggregators that index content across the network. These are the basics of how we envision this network working. You can check out the current state of the specs on atproto.com and the code is on GitHub.
We're building a client app called Bluesky on top of the AT Protocol layer. I haven't talked about some of the things Jack Dorsey mentioned in his original tweet, like moderation curation in communities, because these are really application-level experiences that we're still working on.
This year was about length infrastructure and making sure that the stuff that we choose to build is going to be built on a very strong base layer of portability.
We announced a waitlist for a private beta last week, and we got over 60,000 users, which was a lot more than we were expecting for a test group. If you want to get in early and you're willing to give some user experience feedback, DM me on Twitter (opens new window).
We'll see how well this scales. Also, we're hiring. We could use a mobile dev to help out with the app, a front-end UX developer to help us prototype approaches to moderation reputation curation, and systems or protocol engineers to work on the app protocol. If you'd like to join us, reach out.
ATproto.com (opens new window) and blueskyweb.xyz (opens new window) are the relevant websites. If you go there you'll find links to the Matrix Dev Room, the jobs, and everything else so thank you.