
Lassie, a new tool designed to find and retrieve data from both Filecoin and IPFS, started as a way to make Filecoin retrieval easy. It has evolved into the backend of Saturn’s Web3 CDN and an IPFS and Filecoin client. The goal? To bridge the gap between ecosystems, giving users the ability to retrieve content addressed data from both Filecoin or IPFS without running their own nodes.
Lassie works with multiple different protocols and races them. As each protocol gets data, it can put the data into the CAR stream. Lassie then properly returns the data to the user. Building to this point hasn’t been without its trade offs. Lassie runs without a content routing library and relies on asynchronous candidate streams, introducing some challenges, but also wins along the way.
In this Transcription, Hannah Howard, a member of Protocol Lab Network’s Team Bedrock (opens new window), dives into Lassie’s origins, its technical architecture, trade offs made along the way, and where the product is heading.
# The Coordination Problem: Protocols are Easy, Using Them is Hard - 0:48 (opens new window)
I want to talk to you about Lassie (opens new window), which is a new IPFS implementation. This version is going to be a little bit more about ‘how the sausage is made.’ We're going to go into some technical architecture, learn how Lassie works, and explore some of the compromises and wins we made along the way.
Before we dive in, I want to talk about something I call “The Coordination Problem: Protocols are easy, using them is hard”. To illustrate this, I am going to bring up some ‘80s and ‘90s anti-drug propaganda.

To the right is Bitswap, the protocol—very straightforward. To the left is go-bitswap, the library. This is essentially illustrating that when you go from the protocol to an actual implementation, it gets messy. There’s a good reason for that, and that is because Bitswap isn’t just an interface to the Bitswap Protocol, it’s actually an entire retrieval coordination layer. When you make a request to Bitswap, you say, “Give me this CID.” Then you figure out how to get it, how to distribute requests between peers, you figure out how to break up requests, etc.
It’s so complicated that for a long time I had trouble convincing folks at Protocol Labs that they should want to build a retrieval coordination layer—outside of go-bitswap—because they just assumed it was so complicatedly packed that it couldn’t be extracted.
# The Problem Lassie Helps Solve: Coordinating Retrievals - 2:55 (opens new window)
This is actually the core problem we’re thinking about addressing in Lassie: How to coordinate retrievals among protocols that already exist. Interestingly, this has been coming for a little while. I wrote an architectural document (opens new window) in 2021 thinking, “Oh, we'll get to build this multi-protocol thing any day now”. As it turned out, it took a little bit of time but we did have some antecedents. Will Scott built this awesome prototype Web3 (opens new window) retrieval client that essentially worked with the Network Indexer to transfer data over Bitswap and GraphSync in a very simplified way. A lot of the ideas from that prototype were actually fed into Lassie.
# The Journey to Lassie: From a Filecoin Retrieval Client to the Backend Library of Saturn - 3:52 (opens new window)
I want to talk about the actual generation: how Lassie came to be. We started with a particular problem, which might feel a little unfamiliar at IPFS Thing, which is “how do we retrieve data from Filecoin?” There was a product that we built to try and bridge the gap between Filecoin and IPFS. At the time, Filecoin was only speaking GraphSync, and IPFS still only speaks Bitswap. So, we built this server called Autoretrieve (opens new window), which would:
- Listen on Bitswap
- Take requests from Bitswap
- Translate requests into an attempt to find the storage providers that had that data
- Then make a GraphSync request
It was a terrible solution to a problem that we had created ourselves when we built these two different networks. My team, the Bedrock team, got pretty heavily involved in that, and we kept iterating on the Filecoin retrieval part. In particular, we wanted to figure out how to find data on Filecoin quickly and retrieve it quickly.
These are problems that were not initially addressed in Lotus, the original shipping product with Filecoin. We didn’t build a content discovery mechanism into Lotus, but in the intervening time, the Network Indexer came into being, and that allows us to find storage providers that have content on Filecoin. So, we were starting to build coordination around retrieving data from Filecoin through GraphSync, and it was getting complex enough that we thought we should make this a separate project: enter Lassie.
"Lassie is a Filecoin retrieval client. The original mission of Lassie was to make Filecoin retrieval really easy."
People would always say, “How do I get my data back from Filecoin?” We wanted to build a very simple tool you could simply hand to people and say: here's how you get it back. Then I made the mistake of getting on a plane to Switzerland to meet with the Saturn (opens new window) team. When I got there, they told me that the library we built was going to be backing the library of all of Saturn, and it was going to be an IPFS and Filecoin client. Never show up a day late to a conference at Protocol Labs. That’s how Lassie came to be.
What we ended up doing first, the big task, was to add Bitswap into Lassie and by doing that, we have evolved Lassie significantly to be an architecture for arbitrary retrieval over multiple protocols, including finding your content.
# How Lassie Works: A Look Under the Hood of Lassie’s Basic Architecture - 6:56 (opens new window)
So to get into how it actually works, I want to first look at the larger ecosystem it exists in. The primary ecosystem Lassie exists in for the time being is Project Rhea, which is this decentralized gateway architecture. Each Saturn node runs some Saturn software and then it runs an instance of Lassie. Lassie exposes an HTTP interface within the Saturn node.
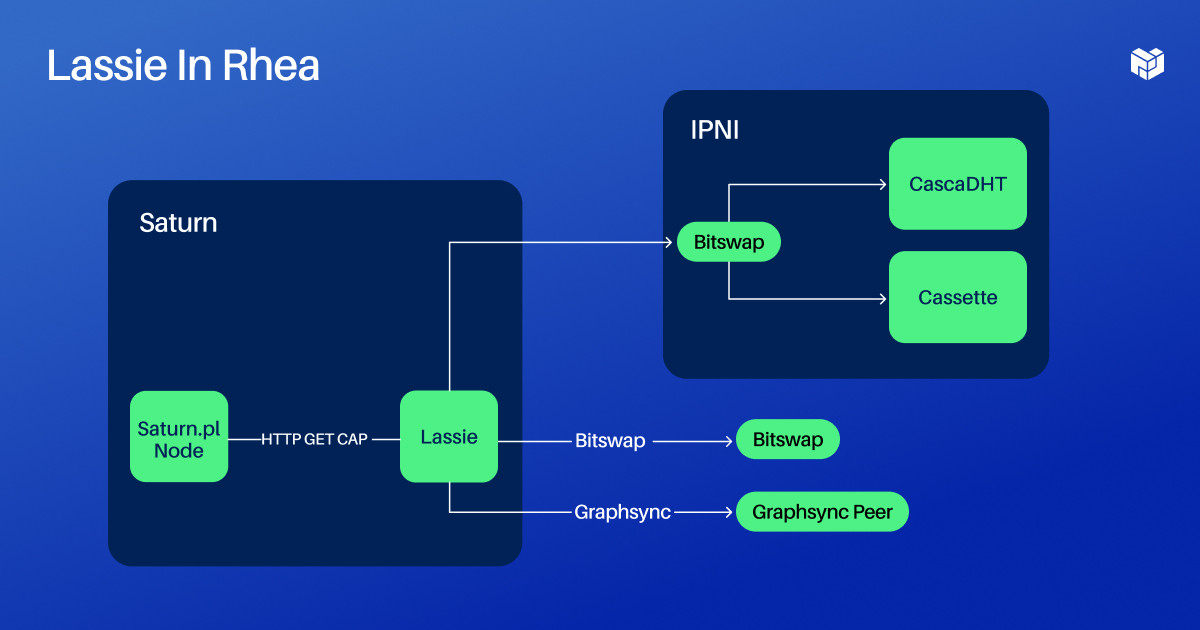
We actually built it that way because Saturn is all written in JavaScript, and we needed an easy way to talk to a Go program. When Saturn nodes don't have things in their NGINX cache, they make an HTTP request to Lassie, and then Lassie basically talks to the Network Indexer as a mechanism for finding things. Then it talks over either Bitswap or GraphSync to people who have the data that you're looking for.

So what's going on inside of the Lassie circle on the diagram? I did my absolute best to keep this as small as possible, but it got complicated.
This is essentially the high level view of Lassie. At the top of Lassie you have essentially two interfaces for interacting with it, this is assuming you're interacting with the Lassie Binary and not interacting it directly with the Library. There's a CLI interface, and there's an HTTP server.
Lassie does not actually have a Block store (a permanent storage of IPFS blocks) and that's mostly true, with a caveat, that we have a very temporary Block store when you make a request. We have essentially a CAR file streaming library that exposes a CAR version 2 Block store to Lassie but then streams a CARv1 back to the client as you get data. The CLI and the HTTP server essentially create a new instance of this CAR stream and they give it to the Lassie library.
The Lassie library has a top level retriever interface that speaks to a client, to the Network Indexer, and essentially, using that client, it makes a network request to the Network Indexer to essentially go from a CID to a list of people who might have the content you're looking for. What we get back from the indexer and from the client is a candidate stream. Essentially, this is an asynchronous stream.
We don't get a list of candidates, we get a stream of candidates that may be coming in over time. When we get a candidate stream, we send that stream into a protocol splitter that divides them up into different protocols that we're going to want to retrieve with. Then we have clients for each protocol that do the retrieval.
The coordination between the protocols right now is actually pretty simple. We race the two different protocols, and because of the way we've built this CAR streaming Library, as each protocol gets data, they can put it into the CAR stream and it properly returns the data to the user. That’s the basic architecture.
# Lassie Doesn’t Have Content Routing - 10:25 (opens new window)
I want to talk about a couple of features you might see. The first is no content routing in Lassie. There's no actual content routing library in Lassie. We work entirely through the Network Indexer and this is an intentional choice. This talk (opens new window) about Bitswap during IPFS Camp highlighted the way one of the biggest mistakes we make in a lot of our software architectures is mixing content discovery and data transfer.
In Lassie, we separate these out by actually moving the content routing to a different service.
We have no option to bring content routing into Lassie. There are a couple of advantages to this:
- It pushes our Network Indexer team to keep making content routing a super awesome solution that has super fast response times.
- It gives us a single stream of candidates.
This does make things a little complicated because in order for the indexer to be performant — particularly because the indexer also talks to things like the DHT and some fallback Bitswap peers that don't announce in the DHT — we want the indexer to send back results as soon as it gets them and continue to send back results as it finds more through mechanisms that may take more time.
# How Lassie Approaches Asynchronous Candidate Streams - 12:22 (opens new window)
We deal with streaming NDJSON Responses
We have to deal with an asynchronous stream. I spent a lot of time thinking about the best way to do it. I used to be a JS programmer and then a Java programmer, and I was really into this thing called Rx. Rx is a kind of reactive programming. It’s super cool. So I went on a whole adventure, like maybe we should be using RxGo. Then I realized that there's a built-in streaming mechanism in Go, and I finally found a use for Go Channels that makes sense to me. That was awesome.
Once I realized, I thought: “Go Channels are just streams.” They're not a magic asynchronous mailbox like Erland. So, that's how we pass around candidates.
# Benefits of Not Having Logic Baked in your Library - 13:20 (opens new window)
There's a lot of cool things you can do when you don't have the logic baked into your actual Library.
When your candidate stream is external you can:
- Use a manual peer list: If you know who you want to retrieve from you can specify it and it will just retrieve from that person.
- Block and filter out peers: This turns out to be really useful when you're in a prototype network that's rapidly sending requests around.
- Force protocols: Because you get results back from the indexer, you can say, “I'm gonna drop all of the candidates that are on this protocol and only use another protocol”.
# The Benefits of a Single Retriever Interface - 14:13 (opens new window)
Another thing that may not be evident from the diagram is that once you exit this content routing interface, essentially in the retriever architecture every single module has kind of the same interface. We like to say “retrievers all the way down,” meaning that you've got a bunch of retrievers, and each retriever tends to have child retrievers if it needs them. This might seem a little bit like astronaut-y architecture, but it does enable you to do some really cool stuff that we've already started using.
For example, you can A/B test different retrievers in production, which is something we need to do especially when it comes to performance. You might have seen that one of the retrievers is called the “protocol splitter.” The simple version of this is that it puts the GraphSync candidates into the GraphSync client, and the Bitswap candidates into the Bitswap client, but you can also do other things. For example, you can send a bunch of Bitswap candidates and not send any GraphSync candidates at first, and then send the Bitswap candidates and get Bitswap going first if you want to prioritize a protocol. So, there's some cool stuff you can do. You can also separate coordination across protocols from coordination within a protocol, which turns out to be pretty useful.
# How Bitswap Works - 15:42 (opens new window)
How does Bitswap work? This is what a Kluge machine is:

We kind of hacked Bitswap with go-bitswap. We essentially pretend to be the DHT for Bitswap. Currently, when Bitswap cannot find its set of local swarms, it goes out to the DHT. Usually there's a delay on it. We remove that delay, put it down to zero, and then we provide it with the peers from the DHT by overriding the interface that it takes to query the DHT. We did this because we needed to get it up and running. We don’t want this to be a permanent state.
It could look a lot of ways. We may end up doing some more Bitswap implementation inside of Lassie. We’re also working with the Kubo (opens new window) team to improve upon the Bitswap architecture so you can get a lower level interface.

One question that's been asked is “is Bitswap permanently broken?” I would ask, is it broken or do we just need to fix it? Part of the problem is that Bitswap tries to do everything. As it evolved over time, it became the uber library for retrieving data on IPFS. The interfaces are super high level, you don't get to tell it what peers you want to retrieve from, you don't get to tell it how it's going to find peers, etc.
What if we built a version of Bitswap that had no more broadcasting of wants to all your friendly other peers—that’s the source of a ton of network traffic? What if we got rid of the concept of content discovery through Bitswap? This was a key optimization we put in but only because there was nothing else. Maybe that doesn't make sense.
What if we just asked for blocks and got them back? If that was all Bitswap was, I think it could work. It may not be the best block request program or protocol but it certainly wouldn’t be the worst.
# The Lassie HTTP Interface - 18:25 (opens new window)
I want to talk a little bit about the Lassie HTTP interface and how it relates to existing HTTP implementations.

Lassie's HTTP server exposes a single path URL interface and it’s: GET/IPFS/CID/path/to/dir?format=car&car-scope=file
If this looks familiar, that's because it's the gateway interface. There are a couple of changes though and this is what enables us. In Lassie, we did not want to do the work of adding trust by sending you back flat files because we really want people to verify their own data. So, we only support CAR files but we do some additional things.
One of the missing components of the ‘so-called trustless gateway interface specification’ in the IPFS Gateway as it stands, is that when you fetch a CAR file, if you fetch it at a path it only sends you the blocks in the CAR file that make up the result at the end of the path. The downside of that is that you lose the ability to verify your data. With Lassie, when you ask for a CID at a subdirectory, we're going to send you the CID and the intermediate blocks, then we're going to send you the data at the end so you can verify it.
We also support some pretty limited but also super useful scopes in what you can request. Right now, by default, all CAR requests attempt to send you an entire DAG from the city request. It just traverses until it gets to the end, and we do support that but we also support some other scopes.
The scopes we support are intended to support a trustful HTTP gateway being able to make the smart requests it needs in order to serve up flat files to another client through Lassie. If you remember the architecture or diagram that we put up for Rhea, the regular IPFS Gateway isn’t just going to be making requests out to Saturn to get back CAR files, but that it's also going to do the translation. So, we need to be able to make intelligent requests that allow us to get the data we need for translations.
The second scope we support is the so-called “Filescope”—the name is a work in progress. The Filescope returns back data and if it's Unix FS data, it returns back exactly what you would expect. It returns back the entire Unix FS entity that you would expect to get if you made a flat file request. That means if you made a request for a file, then it's going to return back all of the blocks that go into that file. If you made a request for the directory, it's going to return back all the blocks that are needed to essentially LS the directory. It’s not going to return all the subdirectories and files underneath it because that could get huge, but the Filescope will allow you to essentially LS.
The one other scope we have is the Block Scope which is just going to return back the single block at the end of the path. We also may have support for byte ranges in Lassie. I was in the middle of working on that on the plane. We support it in Saturn but for architectural reasons we intentionally kept it out of Lassie. The CLI has all these same commands.
Fun fact: this HTTP protocol is the first protocol that we're going to support for back-ends providing data to us. So, we're actually going to be working with a couple of key stakeholders or people who hold a lot of data—namely Filecoin storage providers running boosts and probably Web3.Storage (opens new window)—to add HTTP transfer to Lassie and the interface will just be the same interface that Lassie exposes now.
When we do that, we are still going to verify the data in between, so we're not just going tobe a super-simple proxy. We think that's important because we want to make sure that we're not returning stuff to the user that is not the correct stuff.
# Lassie’s Metrics: Tracking Everything to Get to Performance - 23:03 (opens new window)
To get to performance, you have to measure everything.
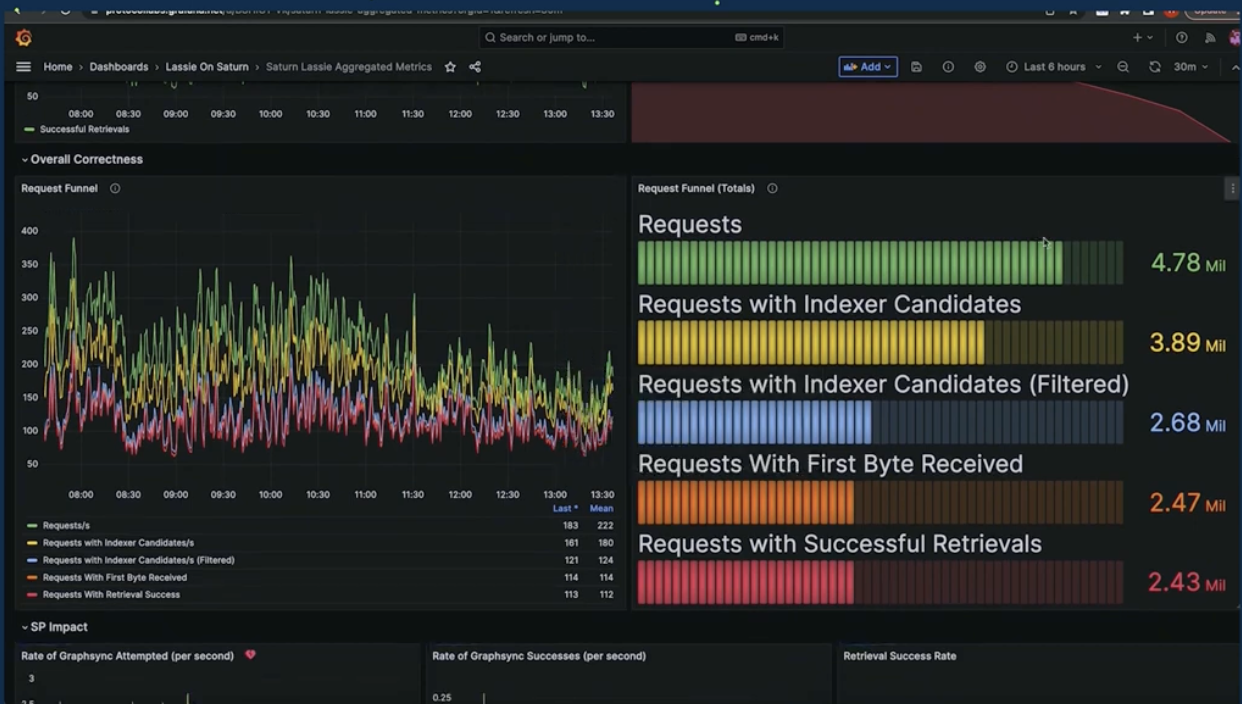
This image is a snapshot of our “Mega Grafana,” mostly tracking Rhea metrics. You can see the entire funnel of requests, you can see where we are losing people. We’re actually losing people when we cannot find their content and because we filter out their content. There’s a bunch of other stuff in here.
We’re very intent on getting Filecoin Storage Providers to be a big part of the Lassie retrieval story, so we've got a ton of metrics on how we’re doing with different Filecoin storage providers and why they're failing. We've got stuff about “time to First Bite,” “time to bandwidth and data transfers,” and how much data we’re moving.
The point is we're trying to track everything super closely so that we can iterate and improve and we've shown this over the course of the Rhea project by having metrics. We’re able to try experiments and see how they affect the metrics. We can iterate from there and make a lot of progress. I think that's going to be our strategy for a long time.
# What’s Next for Lassie: Staying Mostly Stateless - 24:57 (opens new window)

I've said before that Lassie is largely stateless, but when it's up as a server—a long-running process—there are probably some decisions we want to track and make some good decisions about. We want to choose the right peers to get data from. We want to choose the ones that are fastest, the ones that tend to respond successfully, and the ones that may be closest to us. So, right now we are storing some of that information but we want to keep developing that. We want to feed that data into the requests we make to try to coordinate between multiple protocols the absolute fastest way to get data. So we're going to be iterating on that. We want to make good decisions.
If you’ve dug into the Bitswap code, it does a lot of this—there's a lot of really intelligent stuff in there. It's just tied only to Bitswap and so we are sort of making the ‘protocol neutral’ version of that. We're going to use some state in memory, we're not going to write in the disk, and we may not do all of this ourselves. We may also want to delegate out to another party who can perform this at scale more effectively, so we'll see where that goes.
—-
Want to dive deeper into Lassie? Learn how to use Lassie in this Filecoin blog post (opens new window) or watch this PL Engineering & Research video (opens new window) for an in-depth look at the tool and a roadmap for the future.
This talk (opens new window) took place at IPFS Thing in Brussels, Belgium in April 2023